1. chunking : 큰 문서를 작은 조각으로 나누기
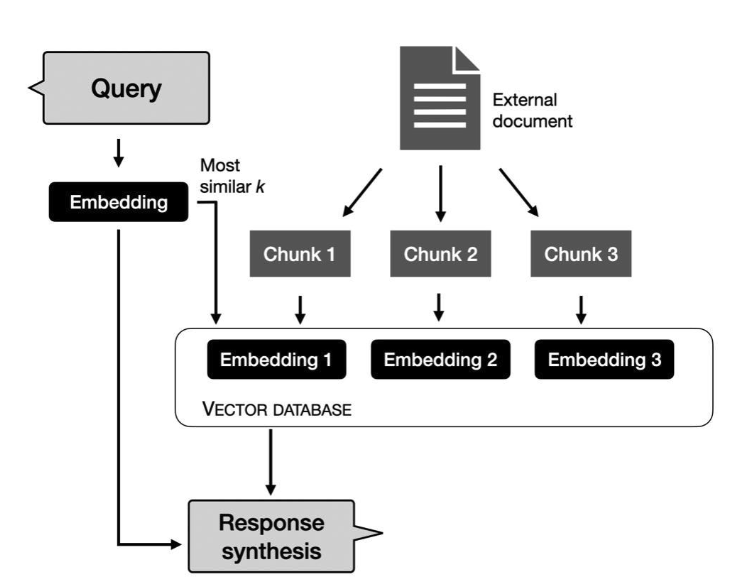
- 임베딩을 진행하기 전에 큰 텍스트를 더 작은 단위로 나누는 과정
- 특히 문서가 너무 길어 벡터로 변환하기 어려운 경우, 청킹을 통해 문서의 의미를 보존허면서 작은 조각으로 나누어 처리할 수 있다.
- ex. 긴 뉴스 기사나 연구 논문을 문단이나 구절 단위로 나누어 각각 벡터화하면 검색과 생성 과정에서 더 효율적이고 정확한 결과를 얻을 수 있다.
- 청킹은 RAG 파이프라인에서 중요한 역할을 한다. 사용자가 검색어를 입력하면, 청킹된 문서들 중에 검색어와 가장 관련성이 높은 조각을 찾아내어 LLM이 적절한 답변을 생성할 수 있도록 돕는다. 이 과정에서 청킹의 크기와 방식은 성능에 큰 영향을 미칠 수 있다.
- 성능개선을 위한 청킹에 천편 일률적인 정답은 없음 → 임베딩 하고자 하는 문서의 종류와 성격에 따라서 같은 청킹 기법을 적용해도 성능이 달라지기도 함.
- ex. 너무 작은 청크는 문맥이 부족할 수 있고ㅡ 너무 큰 청크는 검색 정확도가 떨어질 수 있기 때문에, 적절한 청크 크기와 방식이 중요
2. 고차원 벡터 저장에는 왜 인덱싱indexing이 필요할까?

- 임베딩: 텍스트 데이터를 숫자 데이터로 이루어진 고차원 벡터로 변환해주는 과정
- 검색증강생성 (RAG) 파이프라인에서 임베딩이라는 복잡한 과정을 거치는 이유 → 텍스트로 구성된 외부 데이터(pdf, excel, ppt, txt등)를 벡터 DB에 저장하고 LLM이 필요할 떄 검색해서 꺼내 쓸 수 있도록 해주기 위함.
- 임베딩 모델을 사용하여 텍스트를고차원 벡터로 변환하는 과정은 매우 중요하지만, 이렇게 변환된 벡터들을 효율적으로 저장하고 검색할 수 있도록 하기 위한 인덱싱 작업 역시 빼놓을 수 없음. → 임베딩 목적: 검색을 위함
- 인덱싱이란 한마디로 벡터를 저장할 때, 검색 성능을 극대화할 수 있도록 데이터를 체계적으로 정리하는 과정
- 수많은 고차원 벡터 간의 유사도를 빠르게 계산하고, 사용자가 입력한 검색어와 가장 관련 있는 벡터를 빠르게 찾아내기 필요한 것이 바로 인덱싱(색인작업)
- 고차원 벡터 역시 빠르게 검색될 수 있도록 체계적으로 인덱싱 되어있어야 검색 속도와 정확도를 높일 수 있음 → 벡터화된 텍스트도 효율적으로 검색하고 활용할 수 있음
3. 청킹(chunking), 임베딩(Embedding), 인덱싱(Indexing)의 상호 작용
- 청킹된 텍스트는 작은 단위로 나누어져 벡터화 되고, 그 후 인덱싱을 통해 질서 정연하게 저장
- → 사용자가 검색어를 입력하면 청킹된 벡터들과 유사도 계산을 통해 가장 관련성 높은 문서를 찾아 낼 수 있음
- 이때, 인덱싱이 잘 되어 있으면 검색 시간이 훨씬 빨라지거나, 관련성 높고 정확한 정보가 검색된다.
- 임베딩 모델: 검색증강생성 RAG 파이프라인에서 중요한 역할을 함
- Chunkin & Indexing: 고차원 벡터 간의 검색을 통해 검색증강생성(RAG) 파이프라인을 더욱 빠르고 정확하게 만들어주기 위한 두가지 중요한 기술
- 컨텍스트 길이는 RAG(Retrieval Augmented Generation)에 특히 중요
- 효과적인 청킹 전략을 적용함으로써 사용자의 쿼리의 본질을 정확하게 포착하는 검색 겨롸를 보장할 수 있음
- RAG는 2단계로 동작
- 청킹(인덱싱) : LLM에서 사용할 모든 문서를 수집. 임베딩을 생성하고 임베딩을 LLM에넣기위해 청크로 분할하고, 임베딩을 벡터 DB에 저장
- 쿼리: 사용자가 쿼리를 보내면 LLM이 쿼리를 임베딩으로 변환. 벡터 데이터베이스에서 임베딩과 가장 유사한 청크를 가져옴
반응형
'Machine Learning > RAG' 카테고리의 다른 글
| [ing]RAG 벤치 마크 데이터셋 & 성능 평가 리뷰 (0) | 2025.04.06 |
|---|---|
| [RAG]기술의 각 방법론 및 성능 평가 (0) | 2025.04.06 |
| rag시스템을 위한 주요 청킹 방법 ( + code ) (0) | 2025.02.24 |
| Chunking strategies (0) | 2025.02.24 |
| 정확한 검색을 위한 청킹 전략(Chunking Strategy) (1) | 2025.02.24 |