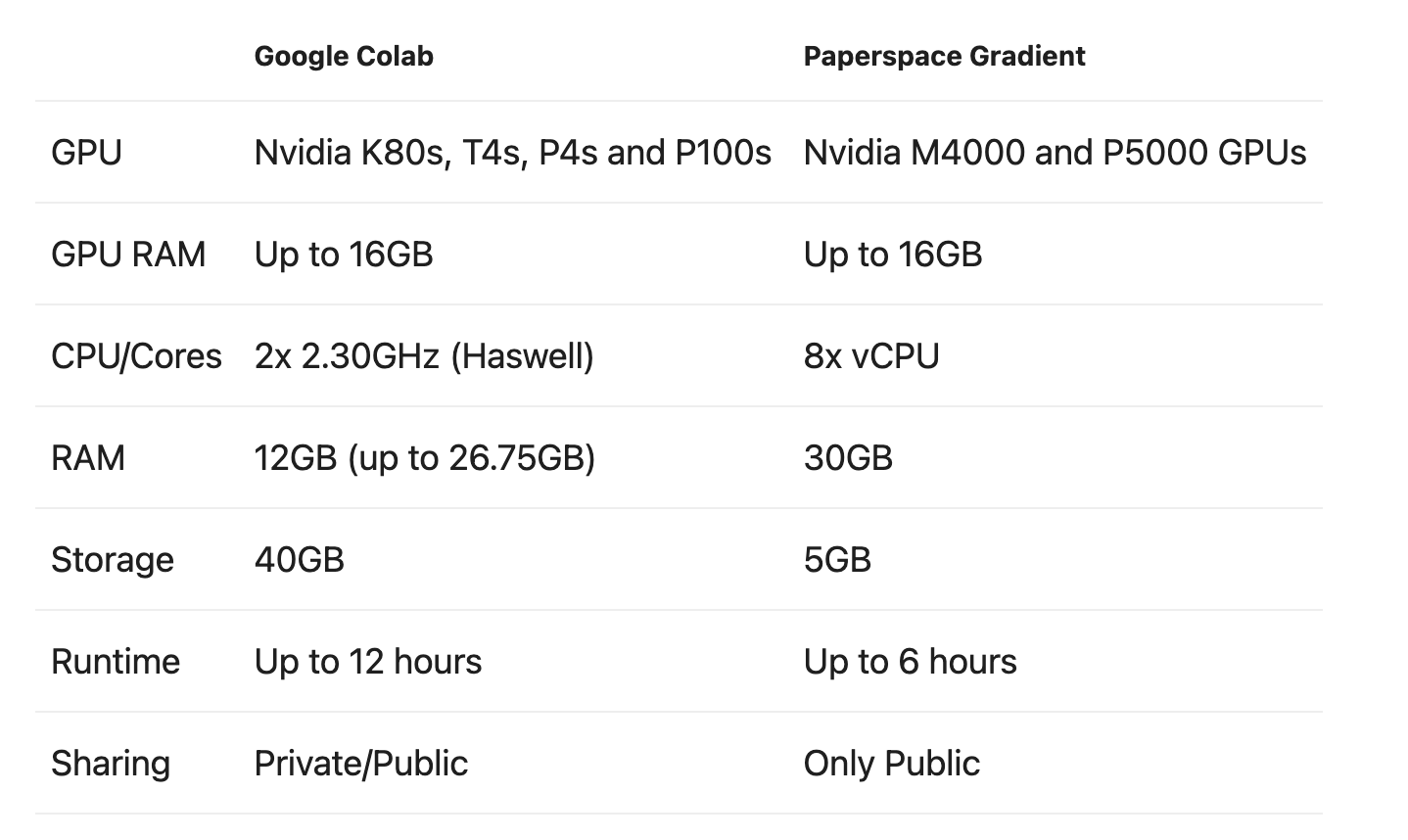
공부하던 중 Gradient가 보이길래 검색해보았당 사양은 colab이 조금 더 좋아 보이나, 필요에 따라 Gradient를 사용해도 좋을 것 같다. 이번에는 Gradient를 사용해봐야겠다. 딥러닝을 공부하려면 고성능 컴퓨팅 자원 (특히 GPU) 를 필요로 합니다. 하지만 가난한 학생 입장에서 고성능 컴퓨터를 맞추기는 쉽지 않습니다. 그래서 많은 사람들이 무료로 고성능 GPU를 활용 할 수 있는 Google Colabatory (이하 Colab)를 사용합니다. 하지만 Colab에도 몇가지 단점들이 있습니다. 대표적인 단점 은 아래와 같습니다. 예기치 않은 세션 종료 (일정 시간 이상 자리비움 혹은 12시간 이상 세션 사용) 세션 종료 시 데이터 소멸 별도의 저장공간 제공 X 세션이 종료 되면 그동안 학..