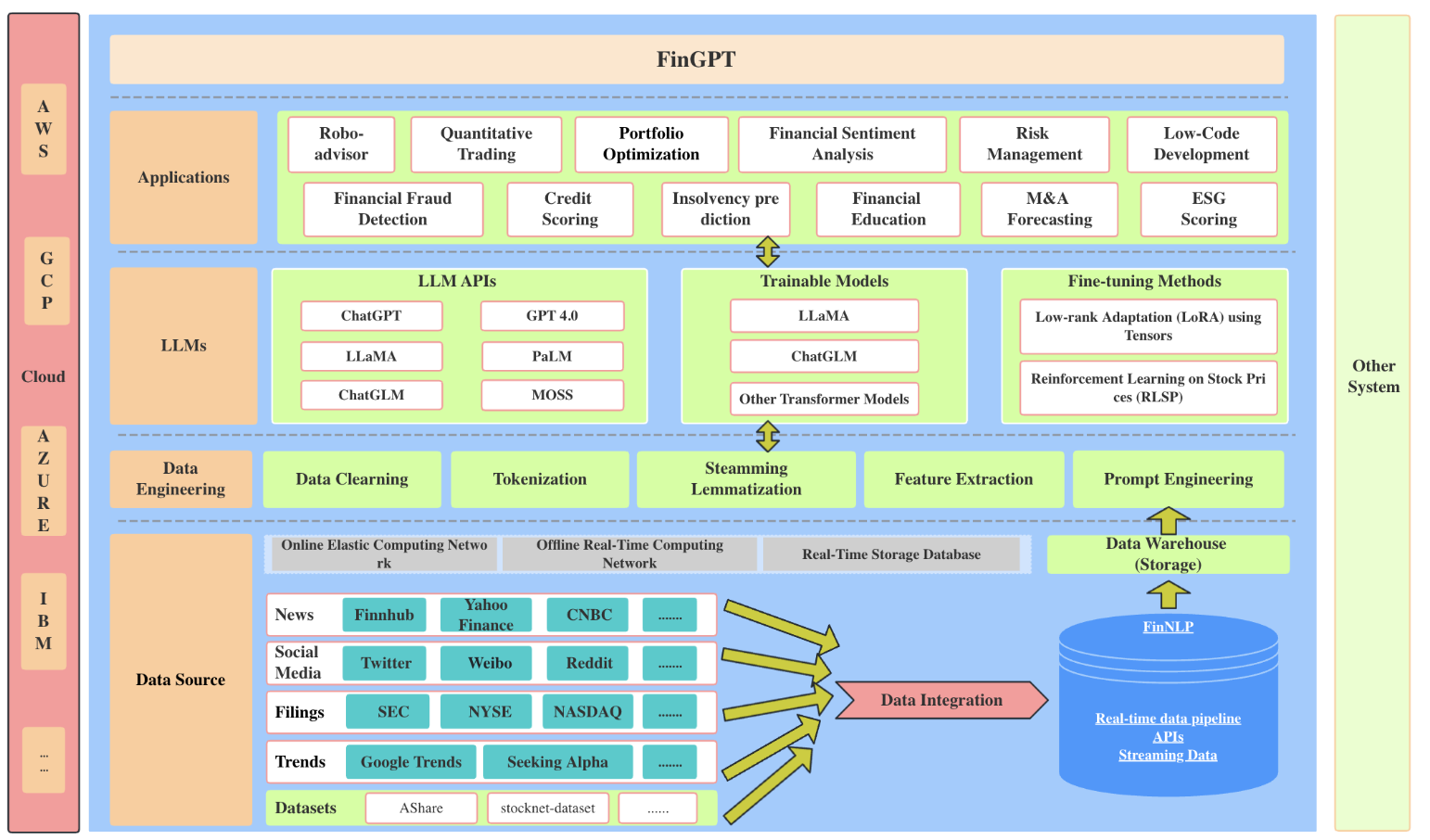
1.Fully Fine-Tuning 이 힘든 이유?LLM의 weight는 최소 1.5~3B 이다.Model을 GPU에 load 하는 것만 해도 웬만한 GPU가 아닌 이상 불가능 하다.모델을 Fine-Tuning 학습하는것도 힘듦forward & Backward, 이를 통한 Model weight update는 gradient 를 전부 GPU에 저장해야 된다.gradient 뿐만 아니라 Optimizer를 위한 이전 기록(=tensor)들도 GPU에 저장해야 한다.결국 Fully Fine-Tuning을 위해서는 모델의 weight수 *2~3배의 GPU vram이 필요하다.weight의 수가 많은 LLM을 Fully Fine-tuning하지 않는 이유가 이것이다.이를 개선 하고자 나온 것이 LoRA d이다...