what is Transformer ?
2023.07.05 - [Machine Learning/NLP] - what is Transformer?
구글의 연구원들이 2017년 논문에서 시퀀스 모델링을 위한 새로운 신경망 아키텍처를 제안했다.
transformer라는 이름의 아키텍처는 기계 번역 작업의 품질과 훈련 비용 면에서 순환신경망 (RNN)을 능가했다.
동시에 효율적인 전이 학습 방법인 ULMFiT가 매우 크고, 다양한 말뭉치에서 LSTM 신경망을 훈련해 매우 적은 양의 레이블링된 데이터로도 최고 수준의 텍스트 분류 모델을 만들어 냄을 입증함.
Transformer 을 기반으로 GPT(Generative Pretrained Transformer)와 BERT(Bidirectional Encoder Representations from Transformers)가 발전 하였다.
이 모델은 트랜스포머 아키텍처와 비지도 학습을 결합해 작업에 특화된 모델을 밑바닥 부터 훈련할 필요를 없애고 거의 모든 NLP 벤치 마크에서 큰 차이로 기록을 경신함
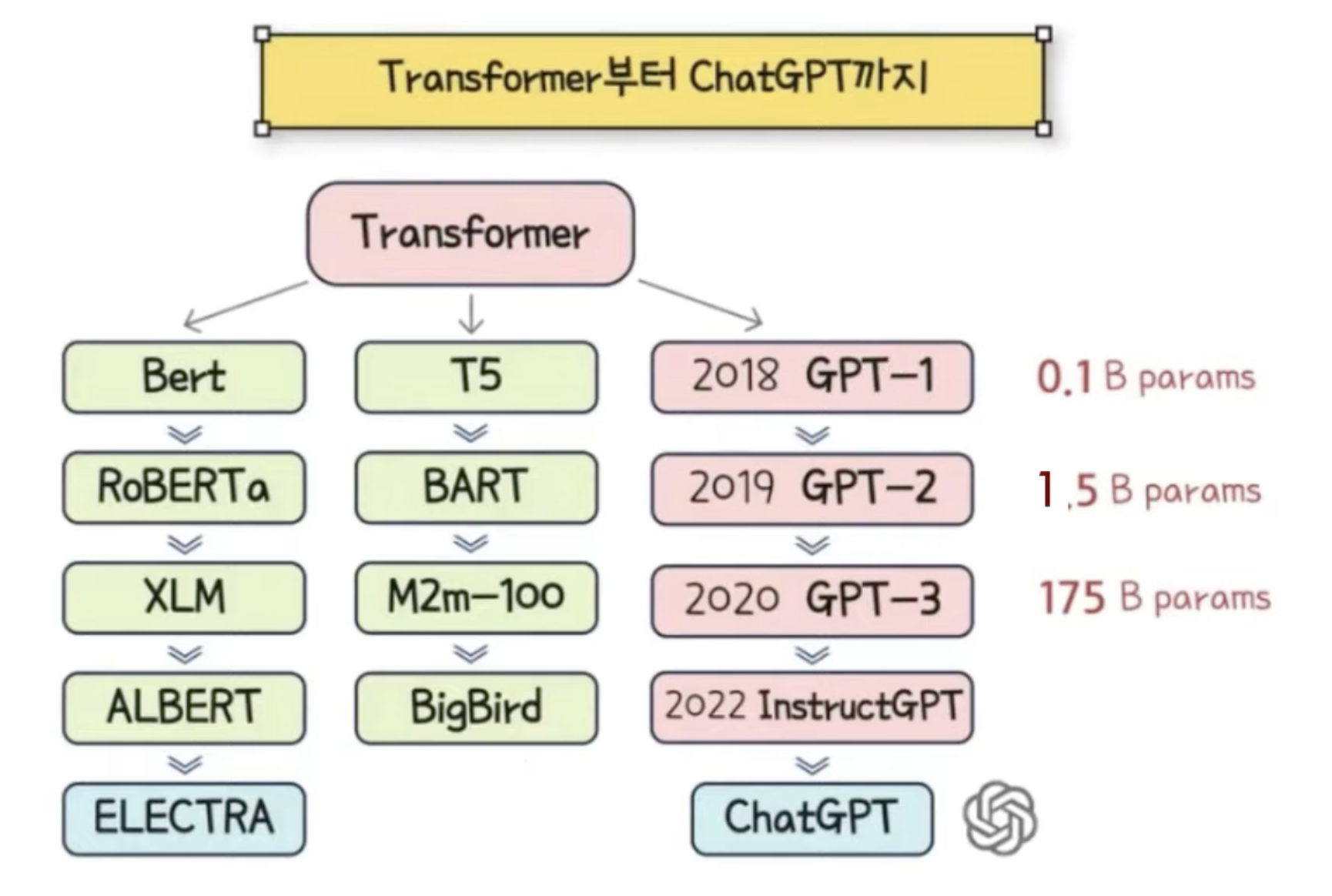
transformer universe
트랜스 포머 모델의 주요 유형은 인코더, 인코더-디코더, 디코더 3가지이다.
Bert (encoder model)
GPT(decoder model)
T5(encoder - decoder model)
연구자들은 사전 훈련용으로 다양한 크기와 특성의 데이터 셋에서 모델을 개발하고 아키텍처를 수정해 성능을 높였다.
Encoder Model
BERT가 대표적인 encoder model.
인코더 유형의 모델은 여전히 연구와 산업 분야 NLU 작업에서 지배적이다. 텍스트 분류, 개체명 인식, 질문답병 등이 이에 속한다.
BERT
BERT의 사전 훈련 목표 두가지는 텍스트에서 마스킹된 토큰을 예측하는 것과 한 텍스트 구절이 다른 텍스트 구절 뒤에 나올 확률 을 판단하는 것이다.
- 마스크드 언어 모델링(MLM) : 텍스트에서 마스킹된 토큰을 예측하는 것
- 문장 예측 (NSP) : 한 텍스트 구절이 다른 텍스트 구절 뒤에 나올 확률
decoder Model
GPT가 대표적인 decoder model.
openAI는 트렌스포머 디코더 모델 발전을 주도함. 디코더 모델은 특히 문장에서 다음 단어를 예측하는데 뛰어나므로 대부분 텍스트 생성 작업에 사용된다. 더 큰 데이터 셋으 사용하고 언어 모델을 더 크게 만드는 식으로 발전이 가속됨.
GPT
GPTsms NLP에서 두가지 핵심 개념. 새롭고 효율적인 트랜스 포머 디코더 아키텍처와 전이학습을 결합했다.
이런 설정에서 모델은 이전 단어를 기반으로 다음 단어를 예측하도록 훈련된다. 이 모델은 BookCorpus에서 훈련되고 분류와 같은 후속 작업에서 뛰어난 결과를 달성했다.
GPT2,3 InstructGPT 설명 : 추가 예정
encoder &decoder Model
T5, BART가 대표적인 endocer-decoder model.
하나의 endocer나 decoder 스택을 사용하여 model을 만드는 것이 일반적이지만, Transformer 아키텍처에는 endocer-decoder 변종이 여럿 있으며 NLU와 NLG 분야에서 새로운 애플리케이션을 만든다.
T5
모든 NLU와 NLG작업을 text to text 작업으로 변환해 통합한다. 모든 작업이 sequence to sequence 문제로 구성되므로 encoder-decoder 구조를 선택하는 것이 자연스럽다.
예를 들어 텍스트 분류 문제의 경우 텍스트가 인코더 입력으로 사용되고 디코더는 클래스 대신 일반 텍스트로 레이블을 생성한다.
T5아키텍처는 우너본 트랜스포머 아키텍처를 사용한다.
이모델은 대규모 크롤링된 C4 데이터 셋을 사용하며 text-to-text 작업으로 변환된 superGLUE 작업과 마스크드 언어 모델링으로 사전 훈련 된다.
BART
encoder-decoder 아키텍처 안에 BERT와 GPT의 사전 훈련 과정을 결합한다. 입력 시퀀스는 간단한 마스킹에서 문장 섞기, 토큰 삭제, 문서 순환(document rotation)에 이르기 까지 가능한 여러가지 변환 중 하나를 거친다.
변경된 입력이 인코더를 통과하면 디코더는 원본 텍스트를 재구성한다.
이는 모델이 더 유연하게 만들어 NLU와 NLG 작업에 모두 사용할 수 있고, 최상의 성능을 달성한다.
Q. 그러하다면, transformer와 BART는 같은 모델인가????
-> 조금 다르다!!!!!!
BART = bert encoder + GPT2 decoder
transformer의 decoder에는 encoder-decoder attention이 있는데, gpt2에는 encoder 블록이 없기 때문에 이 layer가 없다!
Q. Encoder model 과 decoder 모델의 차이는?
BERT : self attention + feed forward layer 로 이루어진 encoder block의 stack 으로 이루어짐
GPT2 : masked self attention + feed forward layer로 이루어진 decoder block의 stack 으로 이루어짐
-> 둘의 차이는 self attention이냐, masked self attenction이냐의 차이!
-> 이 때문에, bert 는 left and right context를 사용할 수 잇음. gpt2는 letft context만 사용 할 수 있다.
bert는 이 bi-directionality 때문에 language generation에서 사용 할 수 없고, gpt는 사용할 수 있는 적합한 모델이다.
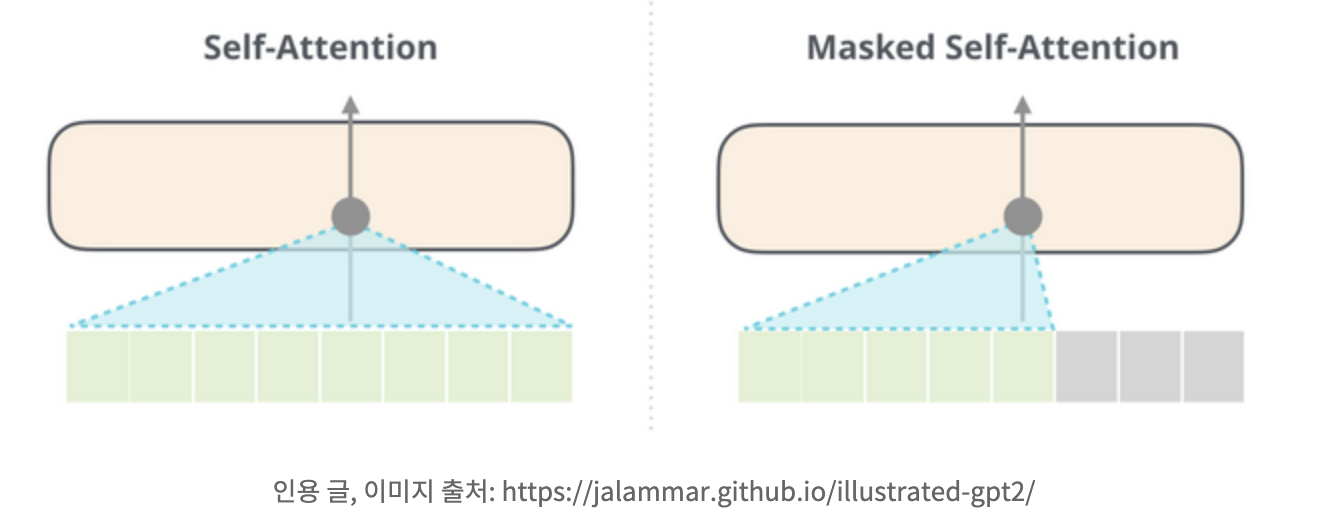
쭝요!!!!
BERT가 사용하는 self attention 과 GPT2가 사용하는 masked self-attention은 다르다!!
일반 self attention block은 자신보다 오른쪽에 있는 token을 계산 과정에서 볼 수 있도록 한다. masked self-attention의 경우 이런 상황을 막는다.
(주의: masked language model과 masked self-attention 은 다르다!!!)
참고: https://m.hanbit.co.kr/channel/category/category_view.html?cms_code=CMS5215583920
참고 : https://heave.tistory.com/73
참고 : https://gnoej671.tistory.com/56
'Machine Learning > NLP' 카테고리의 다른 글
| what is LoRA? (0) | 2024.11.17 |
|---|---|
| [code]BERT example code (0) | 2023.07.20 |
| 자연어처리 흐름 한눈에 보기 (1) | 2023.07.07 |
| [summary]what is Embedding? (1) | 2023.07.05 |