NLP분야에서는 embedding 과정을 거치는데, 자연어를 기계가 이해할 수있는 숫자형태(Vector)로 바꾸는 과정 전체를 임베딩이라고 한다.
임베딩의 대표적 3가지 역할
1. 단어/문장 간 관련도 계산
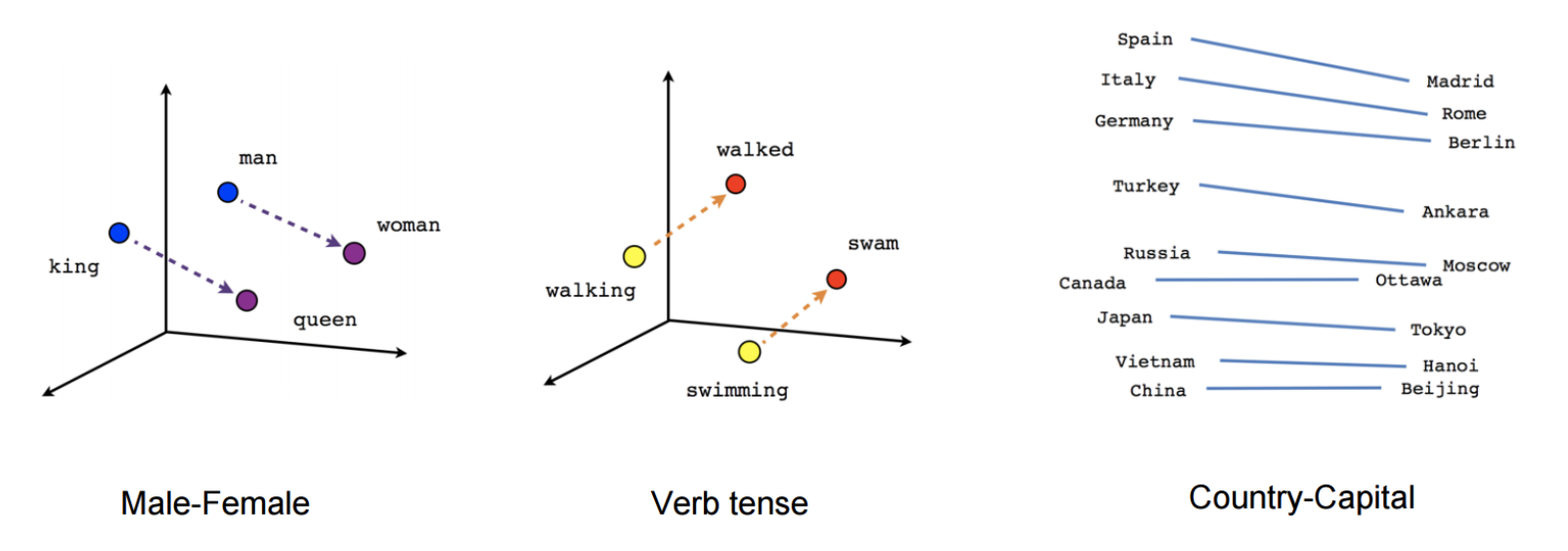
2. 단어와 단어 사이의 의미적 / 문법적 정보 함축 ( 단어 유추 평가)
3. 전이학습 (Transfer Learning , 좋은 임베딩을 딥러닝 모델 입력 값으로 사용하는 것)
임베딩의 자세한 설명 : https://velog.io/@glad415/%EC%9E%84%EB%B2%A0%EB%94%A9Embedding%EC%9D%B4%EB%9E%80
가장 기본적으로 사용되는 벡터화의 방법으로는 One-hot Encoding이 있다.
One-hot Encoding
- 필요한 정보를 담은 하나의 값만 1로 두고, 나머지 값은 0으로 설정하는 방법
- 대부분의 값이 0을 값고 단 한개의 1인 값을 가지는 일종의 Sparse Matrix(희소행렬)으로 표현
- 단어가 많을 수록 벡터 공간만 커지는 비효율 적인 방법
- 원-핫 인코딩은 단어가 무엇인지만 알려줄 분 어떤 특징을 가지고 있는지 설명하지 못한다.
- (-> 이를 해결하기 위해 Dense Matrix 밀집 행렬 로 변환하는 표현법이 제시 되었음)
Text Embedding
텍스트를 표현할 떄는 일반적으로 one-hot Encodding을 사용한 고차원의 희소 행렬(Sparse Matrix)를 사용
- 임베딩 벡터
- 밀집 행렬로 임베딩된 벡터는 각 요서에서 단어의 서로 다른 특성을 나타냄
- 각 요소에는 단어가 관련 특성을 대표하는 정도를 나타내는 0~1사이의 값이 포함됨
- 즉, 이런 임베딩을 통해 텍스트를 단순히 구분하는 것이 아닌 의미적으로 '정의' 하는 것이라 볼 수 있음
- example
- The squad is ready to win the football match
- the team is prepared to achieve victory in the soccer game
- 위의 두문장은 의미는 같지만 비슷한 단어가 거의 없다.
- 하지만 각 문장의 임베딩 벡터에서는 의미적 인코딩이 매우 유사하기 떄문에 임베딩 공간에 서로 가까이 놓임
+@ Embedding 관점에서 BERT
논문 : BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
( https://arxiv.org/abs/1810.04805 )
BERT 는 이름에서 알 수 있둣이, 자연어를 이해하기 위한 양방향 학습 모델을 모두 지원하는 알고리즘이다.
pre-training 방식으로, BERT 등장 이전에 사용되던 임베딩 방식인 word2vec, GloVe, Fasstext보다 더 좋은 성능을 낸다.
use to BERT : [방대한 코퍼스] -> BERT -> [분류를 원하는 데이터] -> LSTM, CNN 등의 머신러닝 모델 -> 분류
코퍼스에 BERT 언어 모델을 적용하고, 이렇게 ' 상태 좋은 임베딩 ' 값을 추가적인 모델에 입력(위에서 언급한 전이 학습)으로 수행하는 구조를 가짐
BERT는 3.3억 단어의 방대한 코퍼스를 정제 및 임베딩하여 학습한 모델이고, 스스로 라벨을 만들고 준지도학습으로 수행했다고 함
단어의 의미를 벡터로 잘 표현하기 때문에, (Embedding 성능이 BERT가 우수) 언어 모델 자체의 성능도 좋고, 결과적으로 모든 자연어 처리 분야에서 좋은 성능을 보이는 범용 언어 모델로 알려져 있음
참고: https://velog.io/@dongho5041/딥러닝-인공신경망의-Embedding이란
[딥러닝] 인공신경망의 Embedding이란?
사람이 사용하는 언어나 이미지는 0과 1로만 이루어진 컴퓨터 입장에서 그 의미를 파악하기가 어렵다. 예를 들어 인간의 자연어는 수치화되어 있지 않은 데이터이기 때문에 특징을 추출해 수치
velog.io
자연어 처리(NLP) - BERT란 무엇인가
# Intro 2018년 11월, Google이 공개한 AI 언어 모델 BERT(버트, Bidirectional Encoder Repres...
blog.naver.com
'Machine Learning > NLP' 카테고리의 다른 글
| what is LoRA? (0) | 2024.11.17 |
|---|---|
| [code]BERT example code (0) | 2023.07.20 |
| 자연어처리 흐름 한눈에 보기 (1) | 2023.07.07 |
| what is Encoder model, Decoder model, Encoder&Decoder model ??? (1) | 2023.07.05 |